
Als LLMs schlagartig an Beliebtheit zulegten, war ich nicht gerade glücklich darüber. Meine Befürchtung war, dass viele Menschen den Hinweis nicht ernst nehmen würden, dass LLMs nicht immer faktisch korrekte Informationen liefern, und dass Fehlinformationen in den kommenden Jahren zu einem großen Problem werden könnten.
Meine Befürchtungen bewahrheiteten sich und erstreckten sich auch ausgerechnet auf mein Lieblingsthema: Malware-Analyse. Ich habe gesehen, wie Internetnutzer überzeugend wirkende, KI-generierte Analyseberichte veröffentlichten, die voller Fehler und falscher Annahmen waren und für die die Nutzer dennoch gelobt wurden. Einige Sicherheitsforscher erklärten, dass sie regelmäßig verschleierten Code in KI-Chats einfügen, die KI anweisen, ihn zu deobfuskieren, und das Ergebnis anschließend als faktisch korrekt übernehmen – obwohl sie wissen, dass es wahrscheinlich Halluzinationen enthält. Der Grund: Es ist einfach. Dabei ist technische und faktische Korrektheit in Malware-Analyseberichten absolut essenziell. Ohne wird jede Analyse völlig nutzlos – bis hin zu dem Punkt, an dem sie sogar schädlich ist.
Trotz all meiner Vorbehalte beschloss ich, dem Ganzen eine Chance zu geben und es gründlich zu testen. Was hat meine Meinung geändert?
Ich wurde von einer KI geschlagen.
Viele von uns Reverse-Engineering-Nerds hängen in Discord-Kanälen herum, um Informationen über Lernressourcen, neue Tools oder Malware-Berichte auszutauschen. Oft bitten Anfänger bei der Analyse von Samples um Rat und Hilfe. Eines Tages bat jemand um Hilfe beim Entpacken einer Malware-Probe. Ich machte mich sofort daran, doch es dauerte eine halbe Stunde, bis ich die zweite Stufe erreicht hatte – und selbst dann gab ich nur einen kleinen Hinweis in die richtige Richtung. Zehn Sekunden nach meinem Beitrag zauberte ein vergleichsweise unerfahrener Reverse Engineer ein Entpackungsskript für alle Stufen aus dem Ärmel. Ich war völlig baff, denn ich bin nun seit 11 Jahren in diesem Bereich tätig und halte mich für ziemlich erfahren. Zumindest erfahren genug, um zu wissen, dass eine Analyse durch einen Anfänger normalerweise nicht so schnell vonstattengeht. Also fragte ich nach, wie das Ergenbis so schnell zustande gekommen war. Die Antwort könnt ihr euch wahrscheinlich denken: Es war KI. Und es war sogar ein sinnvoller Einsatz von KI, denn ein Entpackungsskript lässt sich leicht verifizieren. Man führt es mit dem Sample aus und schaut sich das Ergebnis an.
Also legte ich schließlich meine Gefühle beiseite, schluckte meinen Stolz herunter und baute mein eigenes KI-Analyselabor, um zu sehen, wie gut es funktioniert und ob es eine sinnvolle Ergänzung für mein Tool-Arsenal ist.
LLM-Analyselabor
Mein Setup sieht folgendermaßen aus: Ich habe zwei VMs. Eine mit Remnus und die andere mit Windows 10. Auf der Remnux-VM habe ich Claude und OpenCode installiert und die folgenden MCP-server aufgesetzt:
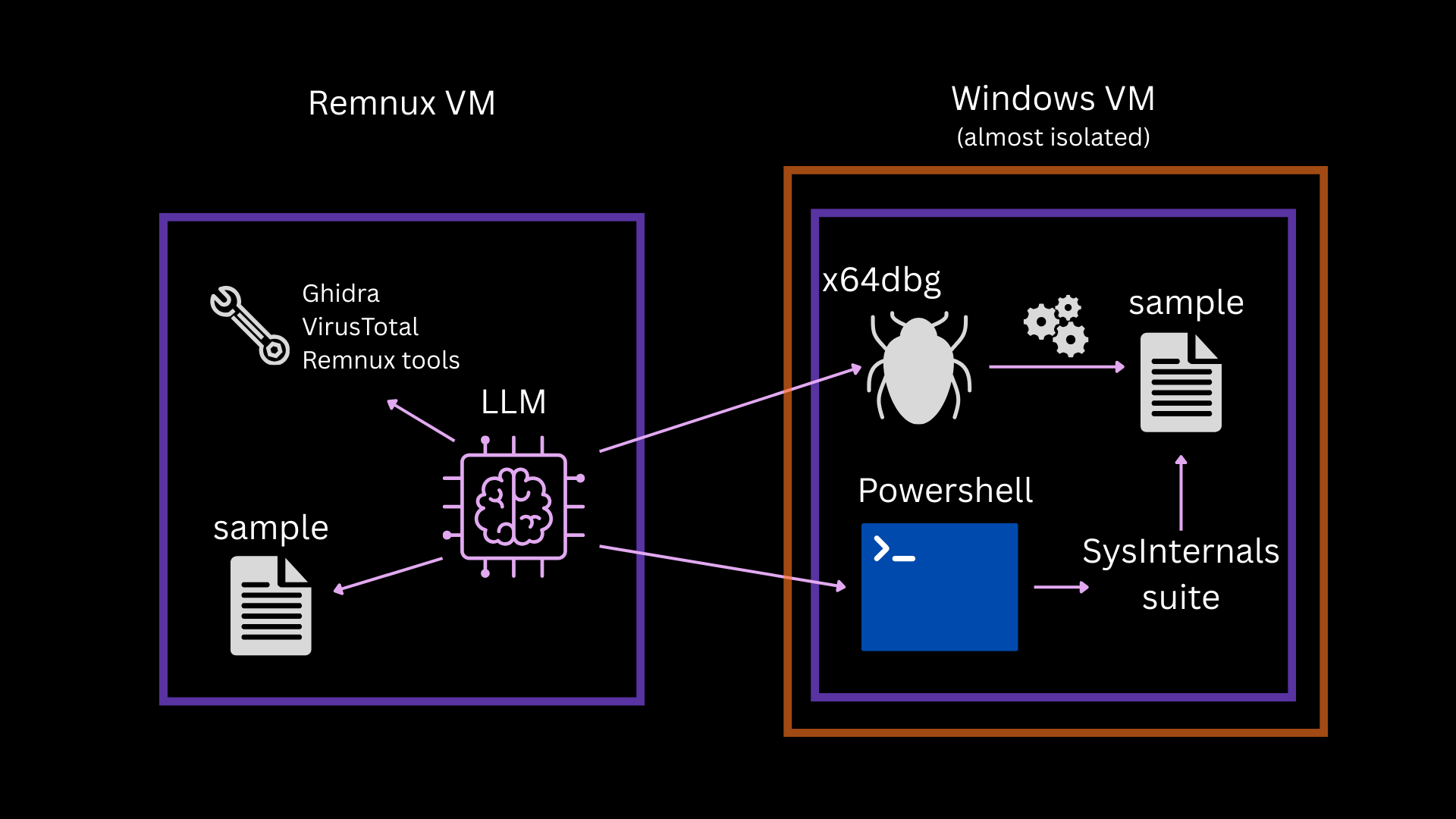
Das SSH- und das x64dbg-MCP sind mit der Windows-10-VM verbunden. Diese VM ist – abgesehen von einem internen Netzwerkadapter – isoliert und dafür vorgesehen, schädlichen Code auszuführen, während Remnux von der KI für die statische Analyse genutzt werden soll. Die Remnux-VM benötigt eine Internetverbindung, damit die KI-Clients funktionieren.
Zunächst testete ich drei Modelle: OpenAI GPT-5.1, OpenAI GPT-5.1-mini und Claude Sonnet 4.6.
Ich begann mit einfachen Samples. Ein Office-Dokument, welches eine bereits ältere Sicherheitslücke ausnutzt (CVE-2017-11882) - das ist ein Equation-Editor-Exploit.
Ich nutzte GPT-5.1-mini, um zu prüfen, ob eine günstigere Option für die Analyse ausreicht. Die Ergebnisse waren jedoch enttäuschend. Einfache Triage funktionierte zwar, aber das ließe sich ebenso mit einem kleinen Skript automatisieren – dafür braucht man kein LLM. Bei komplexeren Aufgaben zog das Modell häufig falsche Schlussfolgerungen und lieferte letztlich keinerlei brauchbare Informationen. Ich gab diesen Ansatz auf – abgesehen von Hashes und einigen Überblicks-Metadaten brachte er keine verwertbaren Ergebnisse.
Im Fall des Equation-Editor-Exploits teilte mir GPT-5.1-mini mit, das Sample sei unbedenklich, da es keine Makros enthalte, allerdings sei die Domain decalage.info sehr verdächtig. Das ist amüsant, denn decalage.info ist die legitime Website von oletools – einer Suite von Python-Tools zur Analyse von MS-Office-Dateiformaten. Das Tool gibt seine Domain im Header aus, und das Modell war nicht in der Lage, zwischen der Header-Ausgabe des Tools und tatsächlich extrahierten Sample-Informationen zu unterscheiden. Wie sich herausstellte, machte GPT-5.1 denselben Fehler.
Ich versuchte, GPT-5.1-mini dazu zu bewegen, über die Emulation einer bestimmten Datei die URL der nächsten Stufe zu ermitteln, doch nach mehreren Versuchen mit Unicorn scheiterte es. Beim zweiten Versuch wies ich es an, Speakeasy für die Shellcode-Datei zu verwenden (weil das bei mir funktioniert hatte), doch auch das schlug fehl. Danach habe ich GPT-5.1-mini für diesen Zweck nicht mehr eingesetzt.

Mit GPT 5.1 und Sonnet 4.6 war es – mit einigen Anpassungen – eine ganz andere Geschichte als das Mini-Modell.
Beim Equation-Editor-Exploit-Sample musste GPT 5.1 zunächst in die richtige Richtung gelenkt werden. Es versuchte anfangs, Makros zu extrahieren, und scheiterte. GPT 5.1 stellte zwar fest, dass es sich um ein ungewöhnliches Sample handelt, konnte jedoch zunächst keinen eindeutigen Nachweis für bösartiges Verhalten finden. Sobald ich es jedoch explizit anwies, nach dem Equation-Editor-Exploit zu suchen, fand es erfolgreich den Shellcode, der die nächste Stufe lädt, emulierte diesen mit Mandiants Speakeasy und gab die URL der nächsten Stufe aus.
Sonnet 4.6 erkannte automatisch, dass es sich wahrscheinlich um einen Equation-Editor-Exploit handelt, lieferte ein korrektes Urteil und identifizierte die Position des Shellcodes. Allerdings konnte es die URL der nächsten Stufe nicht eigenständig extrahieren. Also bat ich Sonnet ausdrücklich, diese URL zu ermitteln – wohlgemerkt eine Information, die ich nur hatte, weil ich das Sample bereits zuvor analysiert hatte. Sonnet durchsuchte alle extrahierten Dateien per Regex nach URL-Mustern, fand jedoch nichts, da die URL vom Shellcode dynamisch zur Laufzeit erzeugt wird. Daraufhin lenkte ich es in Richtung Emulation – was sofort funktionierte.
Anschließend machte ich mit einem deutlich schwierigeren Sample weiter, für dessen Analyse ich zuvor etwa sechs Stunden „klassische Handarbeit“ benötigt hatte, um die Funktionsweise zu verstehen und ein statisches Entschlüsselungsskript zu schreiben, das generisch für ähnliche Samples funktioniert. Das Ziel für die KI war dasselbe: herausfinden, wie sich die Dateien extrahieren und entschlüsseln lassen, und anschließend ein Python-Entschlüsselungsskript erstellen. Hier haben mich die LLMs wirklich beeindruckt.
Sowohl GPT 5.1 als auch Sonnet 4.6 waren erfolgreich – statt sechs Stunden benötigten sie jedoch nur etwa 30 Minuten, um ein samplespezifisches Python-Skript zu erstellen. Selbst wenn ich eine Stunde für die Überprüfung der Ergebnisse aufwende (was man bei LLM-Ausgaben grundsätzlich tun sollte) und das Skript anschließend generisch erweitere, ist das immer noch eine drastische Verbesserung. Das hat mich schließlich überzeugt, dass LLMs ein hervorragendes Werkzeug im Arsenal eines Reverse Engineers sind.
In meinen Vergleichstests war Sonnet 4.6 günstiger und bei denselben Aufgaben etwas langsamer, lieferte jedoch Ergebnisse von ungefähr gleicher Qualität wie GPT 5.1 – und ich wollte kein Vermögen ausgeben. Daher arbeitete ich fortan ausschließlich mit Sonnet 4.6 und Opus weiter, um das Labor und den Analyseprozess zu verfeinern. Oberste Priorität war es, faktisch korrekte und leicht überprüfbare Berichte zu erstellen.
Also entwickelte ich einen Report-Skill (ein Skill ist eine Anweisungsschablone und potentiell Skripte, mit denen ein LLM eine bestimmte Aufgabe zuverlässig auszuführen kann), der nicht nur die finalen Analyseergebnisse auflistet, sondern die LLMs anweist, jeden einzelnen Schritt darzustellen, den ein Analyst zur Verifikation durchführen müsste. Darüber hinaus fügte ich einen Verifikations-Skill für kritische Daten wie IP-Adressen, Hashes, Dateinamen, Pfade, Registry-Keys, Offsets, Zeilennummern und ähnliche Informationen hinzu. Diese Durchläufe verbrauchen leider viele Tokens, da die Samples erneut auf Schlüsselinformationen analysiert werden müssen. Korrekturen aus diesen Verifikationsphasen werden anschließend an den Bericht angehängt.
Ich habe die Pipeline mit Samples belastet, die ich sehr gut kenne, da ich bereits Berichte darüber geschrieben hatte. So ließ sich die Faktenprüfung leicht durchführen.
Dabei habe ich folgendes gelernt:
Man kann Berichten nicht trauen
Selbst mit fünf Verifikationsdurchläufen gibt es häufig Fehler an zentralen Stellen des Berichts – darunter bei IoCs, bei den Beziehungen zwischen Dateien sowie bei Persistenz-Mechanismen und deren Speicherorten. Von LLMs verfasste Analyseberichte sind grundsätzlich nicht vertrauenswürdig. Ich befürchte, dass die Leichtigkeit, mit der man sie erstellen kann, Menschen dazu verleitet, sie für faktisch korrekt zu halten – so wie Bug-Bounty-Programme inzwischen mit LLM-generierten Vulnerability Reports überschwemmt werden und Open-Source-Entwickler enorm viel Zeit darauf verwenden müssen, Pull-Requests zu prüfen, die voll mit AI-Slop sind.
Urteile sind nicht belastbar
Urteile, also die Entscheidung ob ein Sample schadhaft oder sauber ist, sind am problematischsten. LLMs bewerten die Bedeutung ihrer Funde häufig falsch. Das liegt daran, dass sie falsche Annahmen treffen und vorschnell Schlussfolgerungen ziehen. Wenn sie Zugriff auf VirusTotal-Ergebnisse haben, neigen sie dazu, sich bei ihrem Urteil stark auf die Scanner zu stützen. In meinem Arbeitsbereich ist das jedoch unerwünscht, da wir gezielt Samples erhalten, bei denen Scan-Engines oder andere Automatisierungen versagen.
Ich konnte das teilweise korrigieren, indem ich dem LLM untersagte, VirusTotal-Ergebnisse für das Urteil heranzuziehen. Doch das löste das grundlegende Problem falscher Bewertungen nicht.
Es braucht einen erfahrenen Analysten, der gezielte Rückfragen stellt, erkennt, wo Fehlbewertungen entstehen, und die LLMs in die richtige Richtung lenkt.
Zum jetzigen Zeitpunkt kann man LLMs bei der Urteilsfindung nicht vertrauen!
Tooling ist entscheidend
Für Qualität und Geschwindigkeit der Analyse macht es einen enormen Unterschied, ob dem Modell die richtigen Tools zur Verfügung stehen – inklusive klarer Beschreibungen, wann und wie diese einzusetzen sind. Mit der Zeit ergibt es daher Sinn, spezifische Skills für bestimmte Sample-Typen zu erstellen, zum Beispiel einen dedizierten Skill für die JavaScript-Analyse, der geeignete Werkzeuge empfiehlt. Andernfalls verbraucht das LLM unnötig viele Tokens, weil es per Trial-and-Error erst herausfinden muss, was für das jeweilige Sample funktioniert.
Das Hinzufügen des Headless-Ghidra-MCP hat die Analyse ebenfalls deutlich verbessert. Zuvor versuchte das LLM, Disassemblierung mit den integrierten Remnux-Tools durchzuführen – mit ähnlichen Ergebnissen, aber zu deutlich höheren Kosten. Dekompilierung liefert kompaktere und besser verwertbare Ausgaben als reine Disassemblierung und sollte daher bevorzugt werden.
Das von mir verwendete x64dbg-MCP war sehr token-intensiv. Dennoch ist es wertvoll, da sich manche Samples mit Debugging deutlich einfacher analysieren lassen.
Das SSH-MCP ermöglicht es dem LLM, .NET-Binaries dynamisch mit PowerShell zu analysieren oder Skripte zur Laufzeit zu deobfuskieren. Das LLM war sogar in der Lage, einfache Monitoring-Aufgaben zu bewältigen, indem es Sysinternals-Tools aus einem PowerShell-Terminal heraus aufrief. Allerdings benötigt das LLM entsprechende Hinweise, um sich daran zu „erinnern“, dass diese Möglichkeit besteht.
LLMs können mehr Dinge in kürzerer Zeit abdecken
Das Tolle an LLMs ist, dass sie komplexe Programme und Setups in relativ kurzer Zeit detailliert analysieren können. Manchmal erhalten wir Installationspakete von Anwendungen, die aus Tausenden miteinander interagierenden Dateien bestehen. Ein Mensch kann sich unmöglich alle davon im Detail ansehen, weshalb wir viel Zeit darauf verwenden, zunächst die relevanten Bereiche zu identifizieren. Aus reiner Notwendigkeit müssen wir die Analyse irgendwann abkürzen.
Das LLM ist deutlich schneller und findet daher interessante Bereiche, Indikatoren und Dateien, die wir möglicherweise übersehen würden. So entdeckte es beispielsweise in einer Konfigurationsdatei eines Samples einen verbliebenen Debug-Pfad mit einem Projektnamen. Ich hatte dieses Sample bereits ein Jahr zuvor ausführlich analysiert. Es handelte sich um eine sehr große Anwendung mit rund zehntausend Dateien. Die Wahrscheinlichkeit, dass ich dieses Artefakt entdeckt hätte, war äußerst gering.

LLMs verfügen über ein breiteres Wissensspektrum
Jeder Reverse Engineer hat seine Spezialgebiete, in denen er besonders stark ist und über viel Fachwissen verfügt. Ein Grund dafür, dass Malware-Analysten häufig gemeinsam Berichte verfassen, liegt darin, das jeweilige Spezialwissen aller Beteiligten zu nutzen.
LLMs hingegen verfügen auch in den Bereichen über umfangreiches Wissen, die uns selbst weniger vertraut sind. In meinen Experimenten konnte das LLM Funde mit Informationen kontextualisieren, nach denen ich selbst gar nicht gesucht hätte, weil mir nicht bewusst war, dass es sie überhaupt gibt. Gerade wenn man Malware allein und ohne Team analysiert, ist dieser zusätzliche Kontext eine große Hilfe. Er verbessert den Bericht und ganz nebenbei kann man selber noch etwas Neues lernen.
Skripte statt Berichte erstellen
Der große Vorteil von Skripten ist, dass das LLM hier über eine Feedback-Schleife verfügt, die unmittelbar zeigt, ob das Skript funktioniert oder nicht. Diese Art von Rückmeldung gibt es für die meisten anderen Teile eines Berichts in dieser Form nicht.
Indem man das LLM anweist, einen Konfigurations-Extractor, einen statischen Unpacker oder ein Deobfuskationsskript zu erstellen, lässt sich viel Zeit bei der Validierung der Berichtsdaten sparen. Man prüft kurz, ob das Skript nicht „schummelt“ (zum Beispiel einfach eine halluzinierte C2-URL ausgibt, statt tatsächlich etwas zu extrahieren), führt es auf dem Sample aus – und ist fertig. Ein Unpacking-Skript verifiziert beispielsweise nicht nur, welche Payload entpackt wird und in welchem Verhältnis die beiden Stufen zueinander stehen, sondern auch, wo und wie die verschlüsselte Payload gespeichert ist und welche Algorithmen zur Entschlüsselung erforderlich sind.
Ich habe daher als entscheidenden Analyseschritt ergänzt, dass das LLM Deobfuskationsskripte als wiederverwendbare Dateien erstellen soll, anstatt lediglich Einzeiler in der Kommandozeile auszugeben.
Ein eigenes Labor aufzubauen ist einfach
Ein eigenes autonomes LLM-Analyselabor aufzubauen ist einfacher, als man denkt – und es braucht dafür weder die neueste noch die leistungsstärkste Hardware. Wichtig ist jedoch, ein System zu verwenden, das von deinem Hauptrechner getrennt ist.
Ich habe nur ein Wochenende gebraucht, um mein Labor einzurichten. Dafür nutzte ich einen etwa 12 Jahre alten Laptop, den ich auf 16 GB RAM aufgerüstet hatte. Remnux bekam 4 GB RAM, die Windows-VM 8 GB. Als Host-System läuft Debian.
Mit dieser Ausstattung kann ich die Windows-VM mit x64dbg und Ghidra nicht gleichzeitig betreiben, da der Arbeitsspeicher nicht ausreicht. Ich muss also vorher entscheiden, welches Tool das LLM verwenden soll. Wenn ich die Windows-VM nicht benötige, weise ich Remnux 12 GB RAM zu – dann kann es zwei Analysen parallel durchführen, ohne ins sogenannte Thrashing zu geraten. Thrashing bezeichnet einen Zustand, in dem das System mehr Zeit mit Speicherverwaltung verbringt als mit der eigentlichen Codeausführung, was letztlich zum Einfrieren des Systems führt.
Ich empfehle mindestens 32 GB RAM, sofern es das Budget zulässt – insbesondere bei den derzeitigen RAM-Preisen. Ständig entscheiden zu müssen, ob man Debugging nutzen will oder nicht, und manuell zwischen zwei Setups zu wechseln, ist auf Dauer lästig.
Das Gute ist: Das LLM kann viele Teile der Einrichtung selbst übernehmen. Du musst lediglich Remnux und Claude eigenständig installieren. Anschließend sagst du dem LLM, was installiert werden soll, überprüfst, ob es die richtigen Schritte ausführt, und bestätigst sie – fertig. Da alles in einer VM läuft, kannst du bei Problemen einfach einen früheren Snapshot wiederherstellen. Erstelle Snapshots nach allen größeren Änderungen.
Die Abrechnung pro Token eignet sich gut, um Modelle zu testen, wird auf Dauer jedoch sehr teuer. Eine einzelne Analyse kann schnell zwischen 5 und 20 Euro kosten. Für die meisten Anwendungsfälle ist ein Abonnement langfristig günstiger.
(Des-)Informationszeitalter
Es ist überdeutlich, dass autonome LLM-Analysen ein äußerst nützliches Werkzeug in unserem Arsenal sind, das Analysezeiten erheblich verkürzt. Die Automatisierung von Analysen war bislang sehr schwierig, weil jedes Sample einen eigenen Ansatz und eigene Werkzeuge erfordert. LLMs hingegen können selbstständig entscheiden, welcher Schritt als Nächstes sinnvoll ist. Und wenn man sie richtig einsetzt, können wir Reverse Engineers unsere Effizienz steigern, ohne dabei Qualität einzubüßen.
Gleichzeitig weiß ich jedoch, was als Nächstes unweigerlich passieren wird: Kostenpflichtige Dienste mit automatischer, LLM-basierter Sample-Analyse werden auf den Markt kommen – und wie schon bei automatischen Sandboxes mit ihren übereifrigen Maliciousness-Scores werden sie als „Faktenmaschinen“ an Menschen ohne Reverse-Engineering-Hintergrund verkauft. Weil sie auf Knopfdruck beeindruckend aussehende Ergebnisse liefern, werden viele sie missverstehen. Aber auch für Profis wird es schwieriger werden, Wahrheit von Fiktion zu unterscheiden – schließlich wirken diese Berichte technisch äußerst überzeugend.
